Introduction
The rise of AI in courtrooms from drafting legal documents, framing arguments, and even analyzing cases is an ever-evolving tool for greater efficiency in decision making. However, this promise of consistency comes at the price of losing human judgment: emotion, sympathy, and sentiment. While these algorithms were introduced to mediate human inconsistency and prejudice—they can reinforce systemic biases. This study aims to explore the ultimate dilemma: Does the use of Artificial Intelligence in courtrooms enhance or undermine justice by replacing human emotion with algorithmic consistency?
Literature Review
This section reviews the existing academic discourse on the application of artificial intelligence within judicial systems, specifically examining its potential to either enhance procedural efficiency and predictive accuracy or to inadvertently perpetuate biases and diminish the nuanced qualitative aspects of justice (Lu, 2025) Despite growing awareness of algorithmic bias and fairness in AI-assisted decision making, less attention has been given to how different groups of people perceive the legitimacy of these systems in practice (Domínguez & Castellano, 2023; Fine et al., 2025). Experience, profession, and context play a quintessential role in evaluating the integration and adoption of modern-day technology. For example, individuals from a STEM-based background may prioritize the data-driven objectivity AI offers, while those with a background in humanities may emphasize due process and moral responsibility. Understanding these differing perspectives is critical, as public trust and institutional legitimacy play a central role in whether AI systems are ethically accepted .
Scholarly discourse has expanded as modern tools may thwart the moral execution of justice. Some argue AI serves as a means for eliminating human subjectivity, while others categorize it as a threat to due process (Vargas-Murillo et al., 2024). Proponents argue that AI tools can address system overloads such as court backlogs and administrative delays. AI driven document processing systems achieve higher accuracy and proficiency rates than human clerks, allowing employees to redirect efforts to strategic tasks. Transformer-based architectures like Legal-BERT demonstrate strong performance in predicting appellate outcomes, suggesting AI can model legal reasoning for workload management (Kmainasi et al., 2025). However, the integration of AI is generally preferred as a tool to assist human decision-makers rather than replace them.
In contrast, legal scholars warn that AI use in sentencing and risk assessment raises serious concerns about fairness and transparency (Shepherd, 2025). Critics argue that algorithmic systems may reproduce systemic inequalities even when racial variables are excluded (Cossette-Lefebvre & Maclure, 2022). A prominent example is the COMPAS risk assessment algorithm (Rätz, 2022; Schwerzmann, 2021). As a proprietary “black box” system, its internal logic remains undisclosed, which was the central challenge in State v. Loomis (Bavitz et al., 2018). Although the court upheld its use, the case highlighted how algorithmic tools can shape liberty for minorities and expose them to racial biases (Bavitz et al., 2018; Shepherd, 2025; Vuletić & Petrašević, 2020).
Investigations into COMPAS have produced contradictory results regarding bias (Chouldechova, 2016). While some findings suggest predictive accuracy across groups, others, such as the ProPublica study,which found a 45% false positive rate for Black defendants compared to 23% for White defendants (Rätz, 2022). This bias often stems from “proxy” data—such as housing stability, employment, and education—which are deeply correlated with historical discrimination (Cossette-Lefebvre & Maclure, 2022). Human judges take into consideration a defendant’s socioeconomic context and potential for growth, whereas machines lack the “moral architecture” and expressive understanding to handle these qualitative outcomes (Rodger et al., 2022).
Despite these disparities, a mutual consensus exists regarding ethical implications. First, AI should not replace human judgment in sentencing but serve to enhance rulings (Rodger et al., 2022). Second, transparency is an essential condition for ethical use, particularly regarding life and liberty (Contini, 2020; Cutts & Žalnieriūtė, 2025). Third, an algorithm may be statistically accurate yet still erode public confidence (Barysė & Sarel, 2024; Purves & Davis, 2022). Currently, a notable gap exists in how different groups evaluate the fairness of AI-assisted sentencing.This study aims to fill that gap by providing empirical insight into public and professional perceptions of legitimacy (Bühlmann & Kunz, 2011; Fine et al., 2025).
Methodology
This study employs a qualitative approach to examine how individuals from different backgrounds perceive the fairness of AI–assisted decision making in courtroom proceedings. A qualitative method was chosen because it aligns with the research’s goal in understanding reasoning, moral judgment, and interpretation rather than measuring numerical accuracy or prediction performance. By focusing on participants’ explanations, the study aims to capture nuanced perspectives on justice, bias and legitimacy regarding the use of AI.
A cross-sectional comparative survey design was used to collect data from participants at a single point in time. This design is appropriate because the study compares perceptions across individuals of diverse backgrounds rather than tracking changes over time. The comparative approach allows for analysis of how disciplinary background influences ethical evaluations of AI in sentencing, directly aligning with the research question concerning differing perspectives on fairness and justice.
Data was collected through an online Google Form survey consisting of nine hypothetical courtroom scenarios and value-orientation questions involving AI-assisted sentencing and legal decision-making. A total of N = 24 participants completed the survey in full. Participants were not excluded on the basis of any demographic variable, and all 24 responses were included in the analysis.
The sample included participants ranging in age from 15 to 74 years (spanning adolescent students to retired professionals), reflecting a diverse cross-generational spread. Racially, the sample was predominantly South Asian (66.7%, n = 16), followed by White (29.2%, n = 7), East Asian (4.2%, n = 1), and Hispanic/Latino (4.2%, n = 1). While this limits the generalizability of findings to underrepresented racial groups, it offers a meaningful snapshot of how communities with high STEM engagement perceive judicial AI.
In terms of professional and disciplinary background, the sample was distributed as follows: Technology/STEM/Computer Science (20.8%), Law/Humanities/Social Sciences/History (25%), Business/Finance/Marketing (16.7%), Healthcare/Medicine (12.5%), Education/Administrative (12.5%), and Other/No Occupation (12.5%). This distribution allowed for meaningful cross-group comparison between STEM-affiliated respondents and those in law, humanities, or social sciences—the central axis of the study’s “perception gap” inquiry.
Participants were presented with scenarios in which an AI system evaluated defendants using demographic and behavioral data. They were then asked to assess whether the outcome felt fair, select their preferred decision-maker, and explain their reasoning in optional open-ended responses. Participants were divided into three conceptual groups: individuals with a technology-related background, individuals with a background in law or the humanities, and a general control group. Recruitment utilized convenience sampling through educational and professional networks. The survey was administered online and required approximately 7–10 minutes to complete.
Survey Design Rationale
The nine survey scenarios were designed to isolate distinct ethical tensions in AI-assisted justice. Each question targeted a specific moral axis: equality versus individualization (Question 1), competing sources of bias (Question 2), victim versus defendant perspective (Question 3), access to justice (Question 4), accuracy versus accountability (Question 5), pragmatic system comparison (Question 6), trust orientation (Question 7), legal values hierarchy (Question 8), and the appropriate role of technology in law (Question 9).
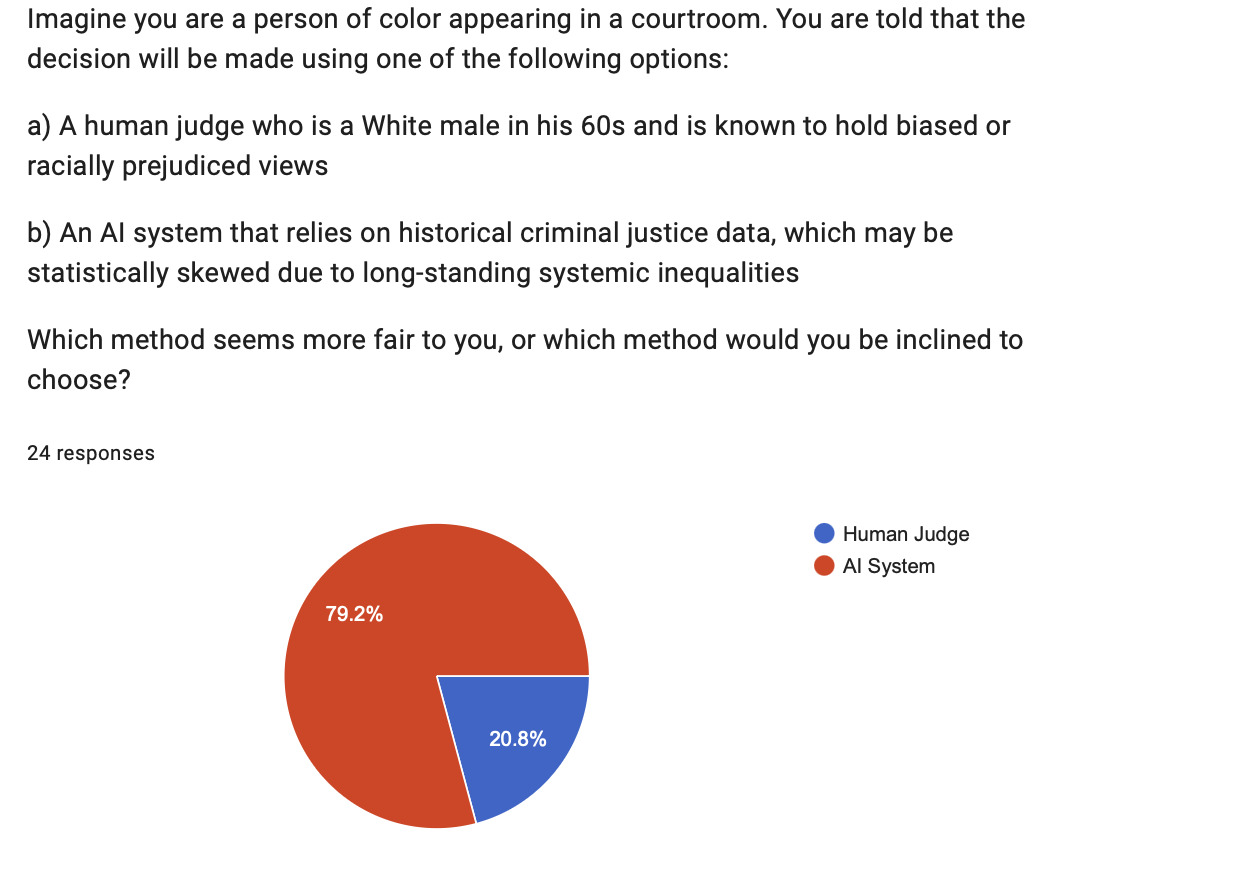
For example, Question 2 asked participants to imagine being a person of color in court choosing between a racially biased human judge and an AI trained on historically skewed data. This scenario was deliberately constructed to force respondents to confront the trade-off between visible and structural bias—a distinction rarely made explicit in prior public perception studies. Questions 7 and 8 were designed as dispositional anchors, establishing each participant’s baseline trust orientation and legal value priorities before comparing those preferences to their scenario-based choices.
Open-ended responses were reviewed thematically using an inductive coding process. Recurring phrases and conceptual patterns were grouped into four core themes: Conditional Trust in AI, Fear of Hidden Bias vs. Visible Bias, Moral Preference for Human Judgment, and Transparency as Legitimacy Proxy. Responses were not independently double-coded given the small sample size, but were analyzed for consistency against quantitative selections.
Participation was voluntary, anonymous, and informed. All participants consented to having their responses used for research analysis prior to completing the survey. Because the survey was conducted as part of an independent student research project and did not involve deception, clinical intervention, or vulnerable populations in a controlled environment, formal IRB review was not required. However, the survey protocol adhered to standard ethical principles of voluntary informed consent, data confidentiality, and transparent research intent.
Despite these design choices, certain limitations must be acknowledged. First, the use of convenience sampling and a relatively small sample (N = 24) restricts the generalizability of findings. Participants were primarily drawn from accessible educational and professional networks, which may introduce selection bias and limit demographic diversity—particularly the underrepresentation of Black and Hispanic respondents, who are disproportionately affected by algorithmic sentencing tools such as COMPAS. Additionally, the hypothetical nature of the survey scenarios may not fully capture the emotional and psychological weight of real courtroom experiences, potentially influencing participant responses. Future research could improve upon this design by incorporating a larger, more representative sample, as well as longitudinal or experimental methods to observe how perceptions evolve over time. Integrating real-world case studies or behavioral data could strengthen the connection between theoretical ethical concerns and practical judicial outcomes.
Results and Analysis
Although this study employed a qualitative framework, several meaningful patterns emerged from the survey data that illuminate how professional background, racial identity, and moral reasoning shape perceptions of AI in the courtroom. Before engaging with the scenarios, participants reported an average support rating of 3.67 out of 5 for AI use in the legal system. After working through all nine ethical dilemmas, that average declined to 3.47 out of 5. This modest but consistent drop suggests that abstract optimism about technology weakens when confronted with morally complex realities—a phenomenon consistent with what Purves and Davis (2022) describe as the erosion of institutional trust under conditions of perceived opacity.
Theme 1: Conditional Trust in AI
The most consistent finding across the dataset was that support for AI was never categorical—it was always conditional. Participants did not oppose AI in principle; they opposed it under specific conditions: when it lacked explainability, when its training data was demonstrably biased, or when it was positioned to replace rather than supplement human judgment.
This conditionality was most visible in Question 1 (Equality vs. Individualization), where 75% of participants preferred a human judge when asked which system they would want judging themselves. However, 79.2% reported that their preference would not change even when asked to imagine judging someone else. This near-identical rate across self-interest and societal framing suggests that the preference for human discretion is not rooted in personal advantage—it reflects a structural belief that individualized judgment is a fundamental feature of legitimate justice, regardless of whose case is at stake.
One STEM-affiliated respondent who initially rated their AI support at 5/5 nonetheless concluded: “At the end the Judge should do his homework, should not be just relying on the information received from AI.” This response encapsulates the conditional nature of trust even among AI proponents: the technology is welcomed as a tool, not a substitute. Another participant elaborated: “Use AI as your low level data organizer, and then use human eye to analyze the data.” Both responses converge on a clear functional boundary—AI for processing, humans for deciding.
Theme 2: Fear of Hidden Bias vs. Visible Bias
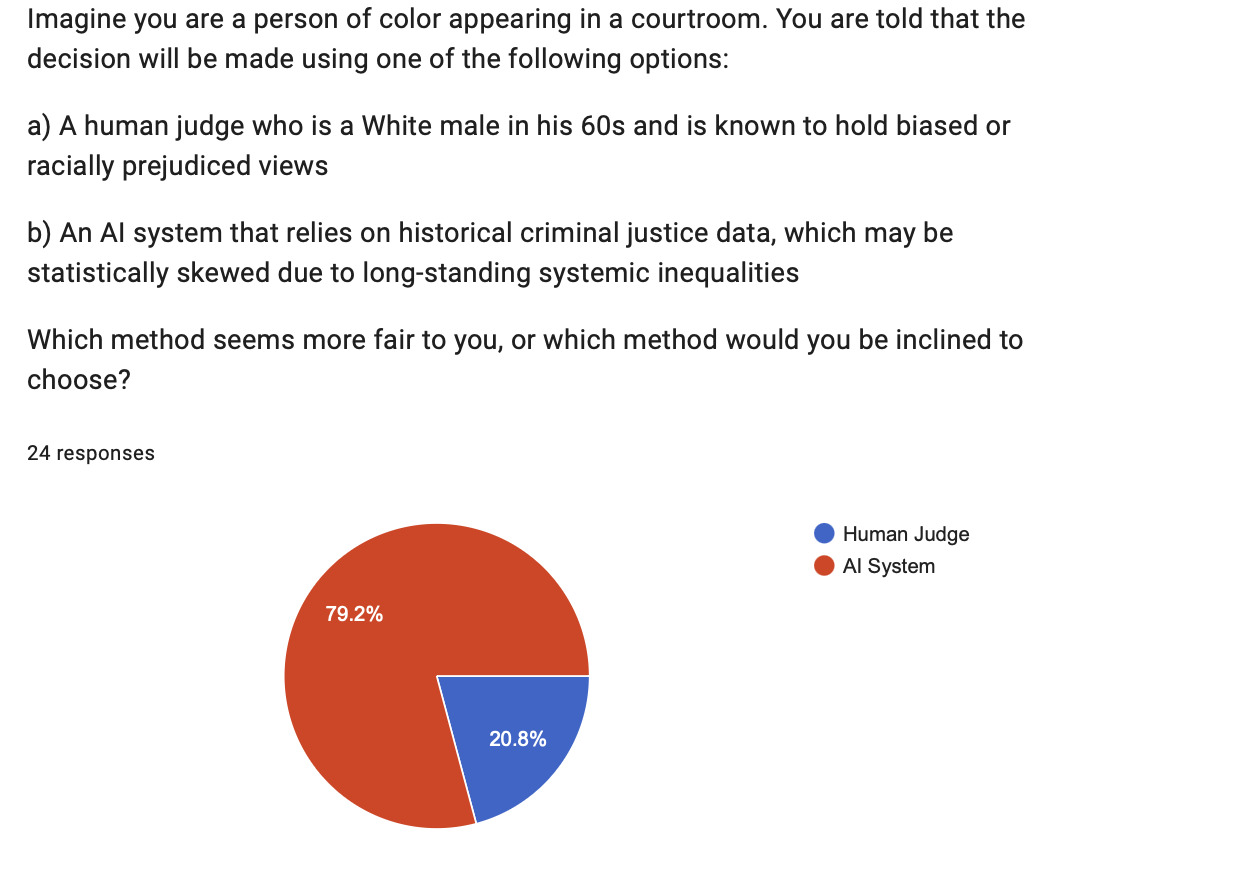
Question 2 (Competing Sources of Bias) produced one of the study’s most striking findings. When asked to choose between a racially biased human judge and an AI system trained on historically skewed criminal justice data, 79.2% of participants chose the AI system. This result appears counterintuitive given broader concerns about algorithmic discrimination—but it reflects a meaningful psychological distinction that deserves careful interpretation.
Participants appeared to reason that explicit, knowable human prejudice felt more immediately dangerous than structural algorithmic bias, which—while potentially more pervasive—is less personally legible. This aligns with what Cossette-Lefebvre and Maclure (2022) describe as the “displacement” of discrimination: when bias is encoded into a system, it becomes harder to identify, challenge, and attribute. Participants in this study may have recognized that a biased human judge is at least a known risk, while simultaneously underestimating the depth of bias embedded in historical training data.
One humanities-affiliated respondent captured this ambivalence: “At my current level of comfort, AI has no place in the legal field. This may change, and I do understand the inherent racial and socioeconomic flaws in the systems. That said, AI is not reliable for this purpose. Fix institutional racism. Don’t use it as a cover to replace human beings with machines.” This response directly resists the framing of AI as a bias-neutral alternative, arguing instead that technological adoption without structural reform would simply launder existing inequality.
The fact that 79.2% selected AI in this scenario—while simultaneously favoring human judges in all other scenarios—illustrates the contextual nature of trust. Participants did not uniformly trust AI; they trusted it more than a demonstrably prejudiced human. This finding has important implications for public communication about algorithmic tools: when the human alternative is visibly compromised, AI’s appeal increases—not because it is trusted, but because it is seen as the lesser risk.
Theme 3: Moral Preference for Human Judgment
Across all scenarios involving emotional complexity, participants consistently returned to human judgment. Question 3 (Victim vs. Defendant Perspective) presented a hit-and-run scenario in which respondents were asked to evaluate whether an AI system or human judge felt more just—both as a victim’s family member and as the driver. Even when holding both perspectives simultaneously, 54.2% preferred a human judge, while 45.8% preferred the AI system. This near-split reflects genuine moral tension: the desire for emotional recognition (as a victim) and the desire for individualized mercy (as a defendant) pulled respondents in different directions.
Question 6 (Overloaded Judge vs. Limited AI) produced an equally close outcome: 50% preferred the AI system for serious crimes, while 45.8% preferred an overworked human judge and 4.2% selected either. This near-tie is itself a finding. When the human alternative is depicted as cognitively compromised—relying on instinct, shortcuts, and case fatigue—support for AI rises to near parity. The moral preference for human judgment is not unconditional; it depends on the quality of human judgment available.
One respondent with a humanities/law background offered a nuanced position that resists easy categorization: “All because no one actor is solely responsible, as with many occurrences in history. A complex tapestry is woven together to produce outcomes both throughout history and today, thus all parties are culpable, but perhaps to different degrees. Before AI is incorporated into the legal system to the degree you described, legislation should be enacted to try and define culpability in such outcomes, although this can be very difficult.” This response frames the issue not as AI versus human, but as a systemic governance challenge requiring institutional design—not just technological caution.
Theme 4: Transparency as Legitimacy Proxy
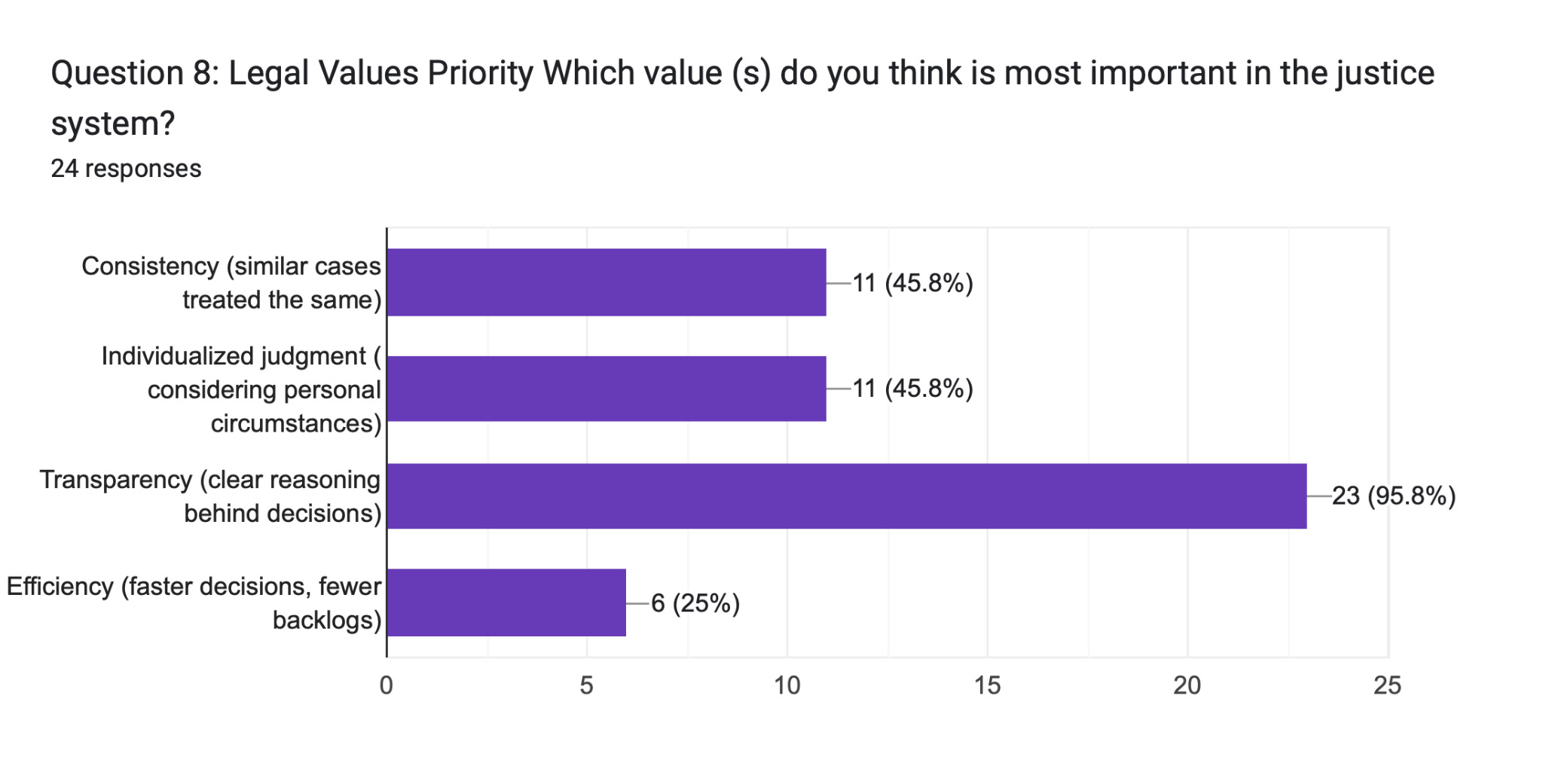
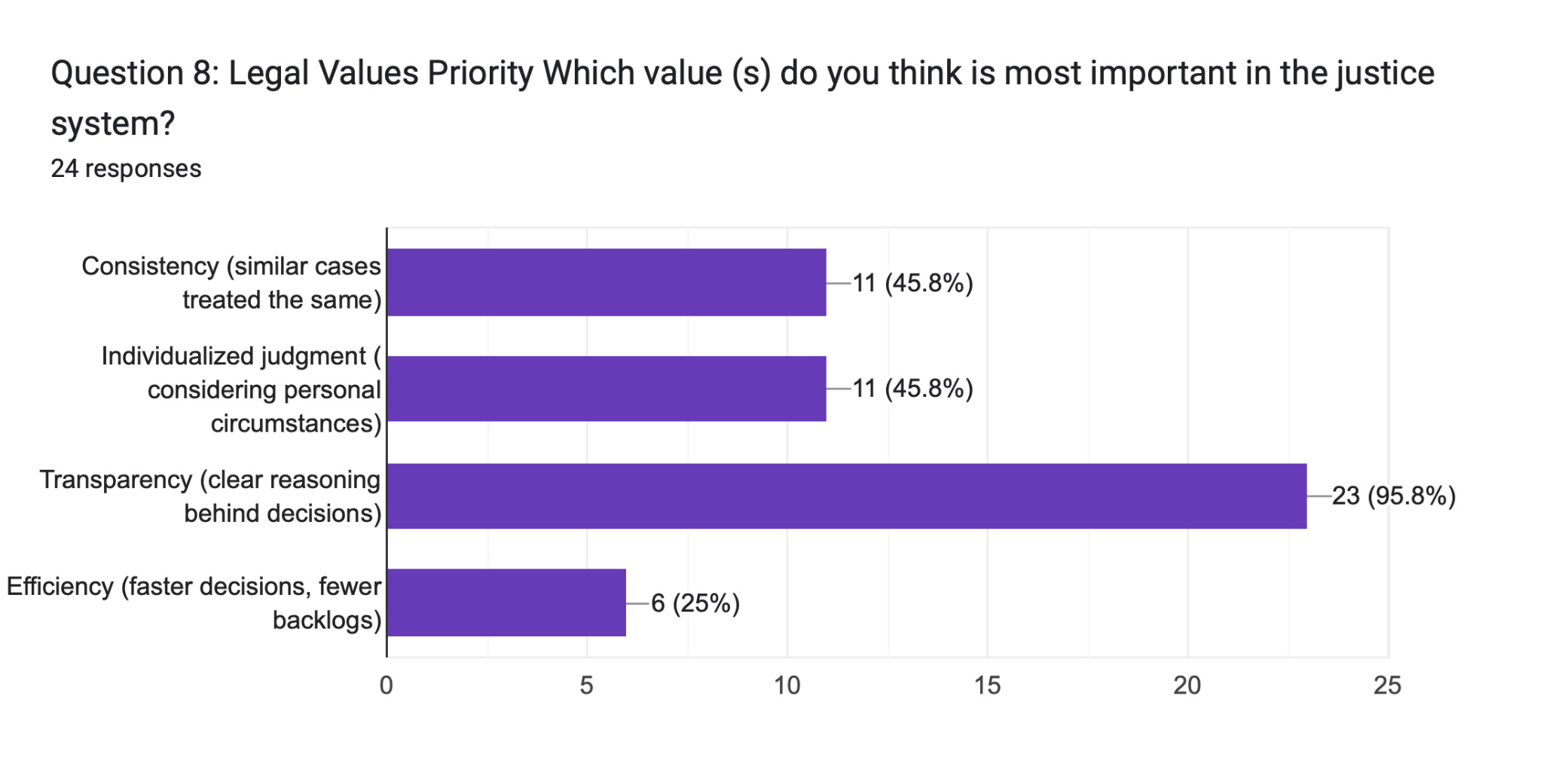
Perhaps the study’s most unambiguous finding emerged from Question 8 (Legal Values Priority): 95.8% of participants—all but one respondent—identified transparency as the most important value in the justice system. This figure surpassed both consistency (45.8%) and individualized judgment (45.8%) by a substantial margin, and dwarfed efficiency (25%). The near-unanimity of this response across all professional backgrounds, ages, and racial identities suggests that transparency functions not merely as a preferred feature of AI systems—but as a prerequisite for their legitimacy.
This finding directly corresponds to the literature on “black box” algorithms. As Contini (2020) and Cutts & Žalnieriūtė (2025) note, opacity in algorithmic systems does not merely limit accountability—it actively undermines the public’s capacity to perceive justice as having been done. In procedural justice theory, the process by which a decision is reached matters as much as the decision itself (Tyler, 1990). When participants overwhelmingly prioritize transparency, they are asserting that they cannot evaluate fairness without visibility into the reasoning behind a decision.
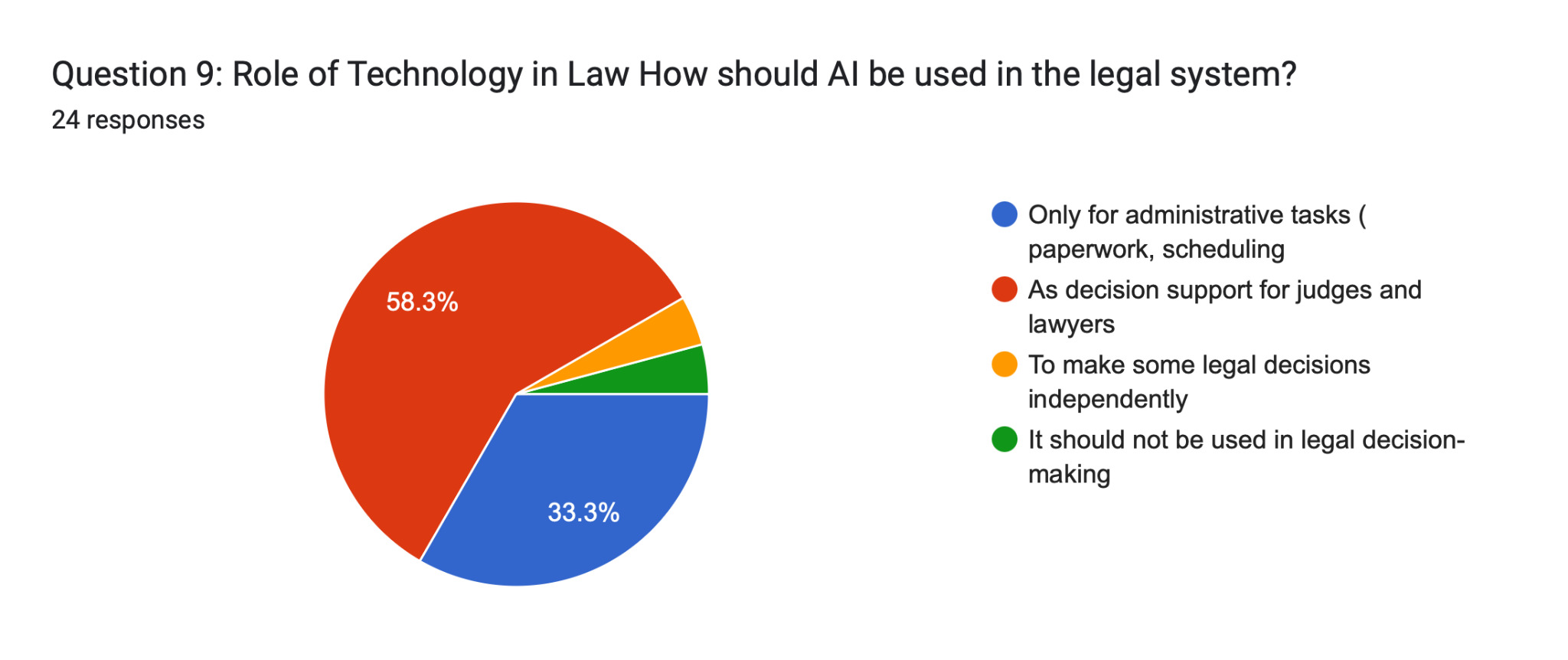
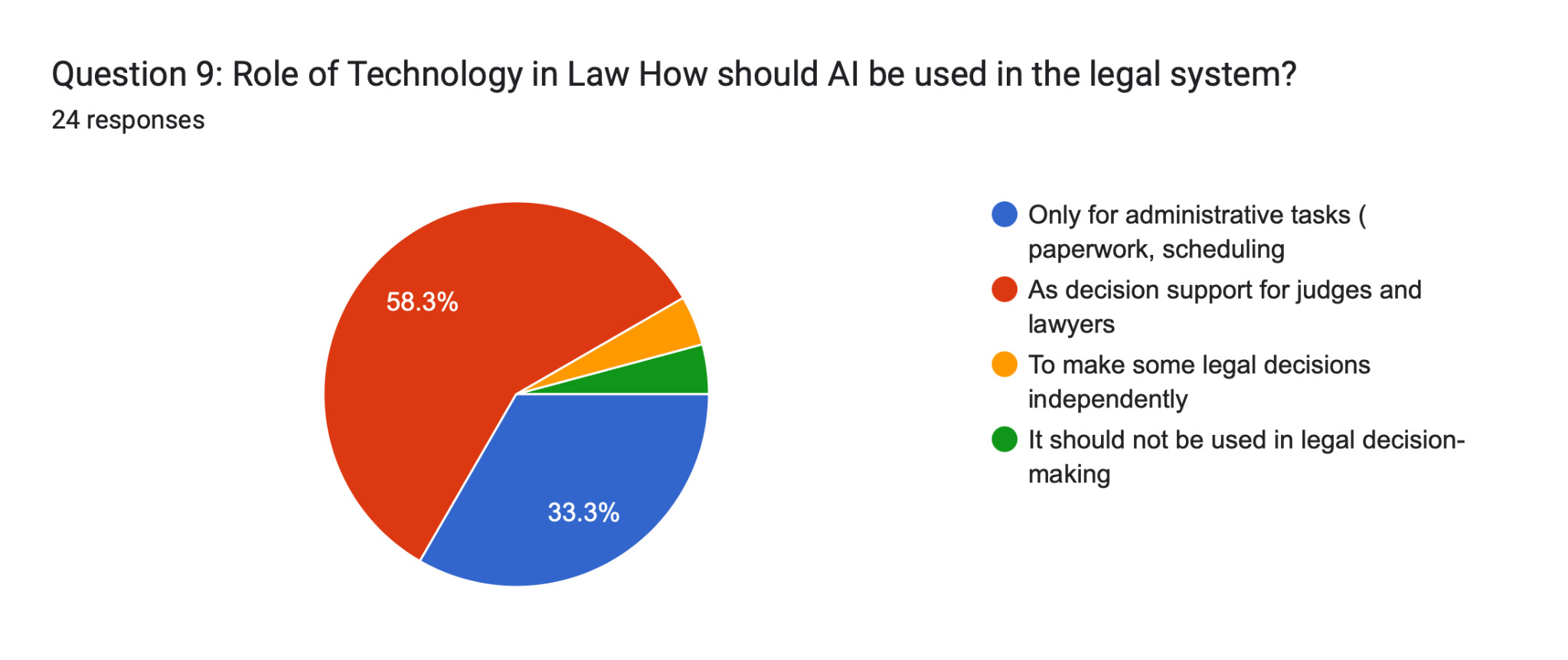
Question 9 further reinforced this: 58.3% of participants indicated that AI should serve as decision support for judges and lawyers, while only 33.3% restricted it to administrative tasks. Fewer than 5% believed AI should make some legal decisions independently, and fewer than 5% wanted it excluded entirely from legal decision-making. These findings suggest that the public has not categorically rejected AI in law—they have defined a specific, bounded role for it: advisory, not autonomous.
The Perception Gap: STEM vs. Humanities Respondents
The study’s original hypothesis anticipated a measurable “perception gap” between STEM and humanities respondents regarding AI’s role in judicial settings. The data provides partial support for this hypothesis, though with important nuances.
STEM-affiliated respondents (Technology/Computer Science, 20.8% of the sample) tended to begin with higher initial support ratings for AI (often 4–5 out of 5) and were more likely to endorse AI in administrative and analytical roles. They showed greater comfort with AI as a decision-support tool, provided that human oversight remained the final check. As one STEM respondent articulated: “I strongly believe using AI in Legal (or any system) can expedite processes—but humans must remain the ultimate arbiters.” Another noted: “If a judge wants to utilize AI, they should understand that there could be serious flaws with the analysis and be held accountable.”
By contrast, humanities and law-affiliated respondents (25% of the sample) were more likely to flag structural concerns about AI adoption—emphasizing due process, institutional racism, and the irreplaceable value of contextual moral reasoning. Several explicitly resisted the framing of AI as a solution to legal inequality, arguing instead that algorithmic tools could mask or entrench existing disparities. The respondent who stated “Fix institutional racism. Don’t use it as a cover to replace human beings with machines” was representative of this perspective.
However, both groups converged on three core positions: AI should not replace human judgment; transparency is non-negotiable; and a hybrid model is preferable to either extreme. The perception gap, therefore, is less about the destination than the journey—STEM respondents focus on how AI can be safely implemented, while humanities respondents focus on the conditions that must first be satisfied before it should be. This distinction has meaningful implications for interdisciplinary AI governance, suggesting that productive policy dialogue must acknowledge both implementation logic and moral precondition.
The findings of this study both support and complicate prior scholarship on public trust in AI-assisted judicial systems. Taken together, they reveal a public that is neither naively pro-AI nor reflexively opposed to it—but rather conditionally receptive, and acutely sensitive to questions of transparency, accountability, and the preservation of human moral agency.
Discussion
The study’s central finding—that 95.8% of participants prioritize transparency above all other legal values—directly corroborates the theoretical frameworks advanced by Contini (2020), Cutts and Žalnieriūtė (2025), and Purves and Davis (2022). These scholars argue that algorithmic legitimacy is not a function of accuracy alone, but of perceived procedural fairness. An AI system that produces correct outcomes through an opaque process fails the test of institutional legitimacy even when it succeeds technically. The participants in this study appear to have internalized this principle: explainability, not efficiency, is the currency of trust.
This finding also resonates with Fine et al. (2025), whose work on public perceptions of AI in courtroom decision-making found that procedural justice—the sense that one’s case was heard through a fair process—significantly mediates acceptance of AI-assisted outcomes. The current study extends this finding by demonstrating that transparency is not merely a preference but a threshold condition: 58.3% of respondents supported AI as decision support, but virtually none (less than 5%) endorsed autonomous AI decision-making. The line between support and autonomy is precisely where transparency collapses.
The racial bias findings—particularly the 79.2% who chose an AI system over a demonstrably biased human judge in Question 2—partially challenge and partially confirm Chouldechova’s (2016) analysis of the COMPAS false positive disparity. While Chouldechova demonstrates that algorithmic tools can encode racial inequity at scale, the participants in this study suggest that the perception of algorithmic bias remains less vivid and less threatening than visible human prejudice. This gap between statistical harm and perceived harm is a critical challenge for public education about algorithmic justice: systems that quietly replicate discrimination may be tolerated precisely because their bias is structural rather than legible.
The “perception gap” introduced in this study refers to the measurable difference in how STEM-affiliated and humanities/law-affiliated respondents evaluate the legitimacy, appropriate scope, and preconditions for AI in judicial settings. It is operationalized here through cross-group comparison of initial support ratings, scenario-based preferences, and open-ended reasoning patterns.
Why do STEM respondents lean toward AI? The data suggests that STEM-affiliated participants approach AI through a framework of optimization and error reduction. They are less likely to view AI as a values-laden actor and more likely to view it as an imperfect but improvable tool. Their concerns are practical—about data quality, accountability mechanisms, and implementation standards—rather than philosophical. This aligns with what sociologists of knowledge describe as “epistemic culture”: the disciplinary habits of thought that shape how individuals evaluate evidence and make judgments (Cetina, 1999).
Why do humanities and law respondents emphasize moral agency? Participants from these backgrounds consistently framed AI adoption as a question of institutional values, not technical capacity. They were more attuned to the historical record of legal discrimination, more skeptical of algorithmic neutrality claims, and more insistent on the irreducibility of human moral reasoning. As one respondent argued, the legal system’s incremental progress toward justice is a product of human interpretation and advocacy—not algorithmic calculation. To delegate moral judgment to a machine is, in this framing, to misunderstand what justice requires.
What does this mean for policy? The perception gap suggests that effective AI governance in legal contexts will require bridging two distinct epistemic communities. Policy frameworks that speak only to technical standards (explainability requirements, audit protocols, bias testing) will satisfy STEM-oriented stakeholders but fail to address the deeper moral and institutional concerns of legal and humanities communities. Conversely, frameworks that invoke moral principles without engaging technical realities will be dismissed as impractical. A genuinely interdisciplinary governance model must address both: not merely what AI systems can do, but what institutional conditions must be in place before they should.
The data raises a critical question that existing literature has underexplored: should AI be regulated differently in sentencing versus administration? The participants in this study offer a clear directional answer. Question 9 shows that 58.3% support AI as decision support for judges—a role that presupposes human oversight and review—while only 33.3% restrict it to paperwork and scheduling. This suggests public acceptance of a tiered model: AI is welcome in the analytical layer but not the decisional layer of justice.
This tiered model has concrete implications for legislation. Courts and lawmakers might consider distinguishing between Class I AI tools (administrative and analytical, subject to lighter regulatory oversight) and Class II AI tools (sentencing-proximate or outcome-influencing, subject to mandatory transparency requirements, bias audits, and judicial accountability protocols). Question 5’s accountability data is instructive here: 41.7% of respondents attributed responsibility for an unjust AI-driven outcome to “all of them” (judge, developer, and legal system), while 37.5% attributed it to the judge alone. This distributed understanding of responsibility suggests that the public already conceptualizes AI error as a systemic failure—not an isolated technical glitch—which argues for systemic regulatory responses rather than individual liability frameworks.
One respondent articulated this systemic view with particular clarity: “All because no one actor is solely responsible…thus all parties are culpable, but perhaps to different degrees. Before AI is incorporated into the legal system to the degree you described, legislation should be enacted to try and define culpability in such outcomes.” This response effectively outlines a precautionary governance principle: accountability frameworks must precede—not follow—AI adoption.
For AI developers, the implications are equally clear. Question 7 reveals that 87.5% of respondents prefer a “balance of both” data-driven and human judgment—far exceeding those who trust either alone. This is not merely a preference for moderation; it reflects a principled rejection of monocausal decision-making in high-stakes contexts. Developers building tools for legal environments must therefore design for human-in-the-loop workflows by default, not as optional features. Transparency—not just accuracy—must be a primary design criterion.
Finally, the access-to-justice findings from Question 4 deserve policy attention. When informed that 92% of low-income Americans lack adequate legal representation for civil matters, 70.8% of respondents supported allowing AI lawyers to operate within the legal system—even knowing their limitations. However, 66.7% selected a hybrid model when asked whether they would personally use an AI lawyer, and only 8.3% said yes outright. This gap between societal support and personal willingness reflects an important asymmetry: participants are more willing to extend AI’s benefits to others than to accept those same trade-offs themselves. Policymakers must address this asymmetry honestly, rather than assuming that public support for access-to-justice AI translates into endorsement of reduced quality standards.
Conclusion
If justice were a diet plan, this study suggests that no one believes in extreme restriction. Sustainable health comes from balance—exercise, nutrition, and flexibility working together. In the same way, the participants in this study did not want a courtroom powered entirely by AI, nor one relying solely on human intuition: they wanted balance.
The findings of this study suggest that the public is not choosing between AI and judges. They are designing a system that must work through integrated data, discretion, transparency, and shared accountability. Across professional backgrounds and racial identities, support for AI is conditional. Participants leaned toward AI when explicit human prejudice was present, yet returned to human judgment when emotional nuance and individualized justice mattered. Transparency outranked efficiency in every configuration, and hybrid models dominated nearly every scenario.
The awareness of systemic bias complicates technological optimism. An algorithm trained on biased data may quietly replicate it. While AI reliance is trending upward, participants made it clear: justice must remain human-centered. Integration must prioritize mechanisms that preserve human oversight, ensuring ethical considerations and contextual nuances are applied. The future of AI in courtrooms, according to this study, is not replacement—it is partnership.
As decision-making becomes increasingly shared between humans and machines, the challenge is not only to preserve fairness, but to ensure that justice remains accountable to those it serves. AI may function like a data-rich advisor: providing patterns, flagging risks, and increasing analytical capacity. But just as an advisor cannot bear the moral weight of a judge’s decision, an algorithm cannot inherit moral agency. The question is not whether AI belongs in the courtroom—it already does. The question is whether we have built the institutional architecture to ensure it serves justice, rather than the reverse.
Ultimately, this research suggests that the public is not choosing between AI and judges. They are designing a system that must work like a balanced diet — integrating data, discretion, transparency, and shared accountability.
Because in the pursuit of justice, balance is not optional.
It is foundational.
As decision-making becomes increasingly shared between humans and machines, the challenge is not only to preserve fairness, but to ensure that justice remains accountable to those it serves.